 Semantic Complete Scene Forecasting: The SCSF task consumes a 4D point cloud sequence(here
RGB is just to intuitively show the scene contents) and forecasts the complete scene with semantic labels in the whole space in
the next frame.
Semantic Complete Scene Forecasting: The SCSF task consumes a 4D point cloud sequence(here
RGB is just to intuitively show the scene contents) and forecasts the complete scene with semantic labels in the whole space in
the next frame.
IGPLAY dataset
The IGPLAY dataset contains 1,000 scenes lasting 10 timesteps each, where a viewer interacts with various toys among the furniture. Each scene in IGPLAY contains 10 semantic classes in a great variety.
We study a new problem of semantic complete scene forecasting (SCSF) in this work. Given a 4D dynamic point cloud sequence, our goal is to forecast the complete scene corresponding to the future next frame along with its semantic labels.
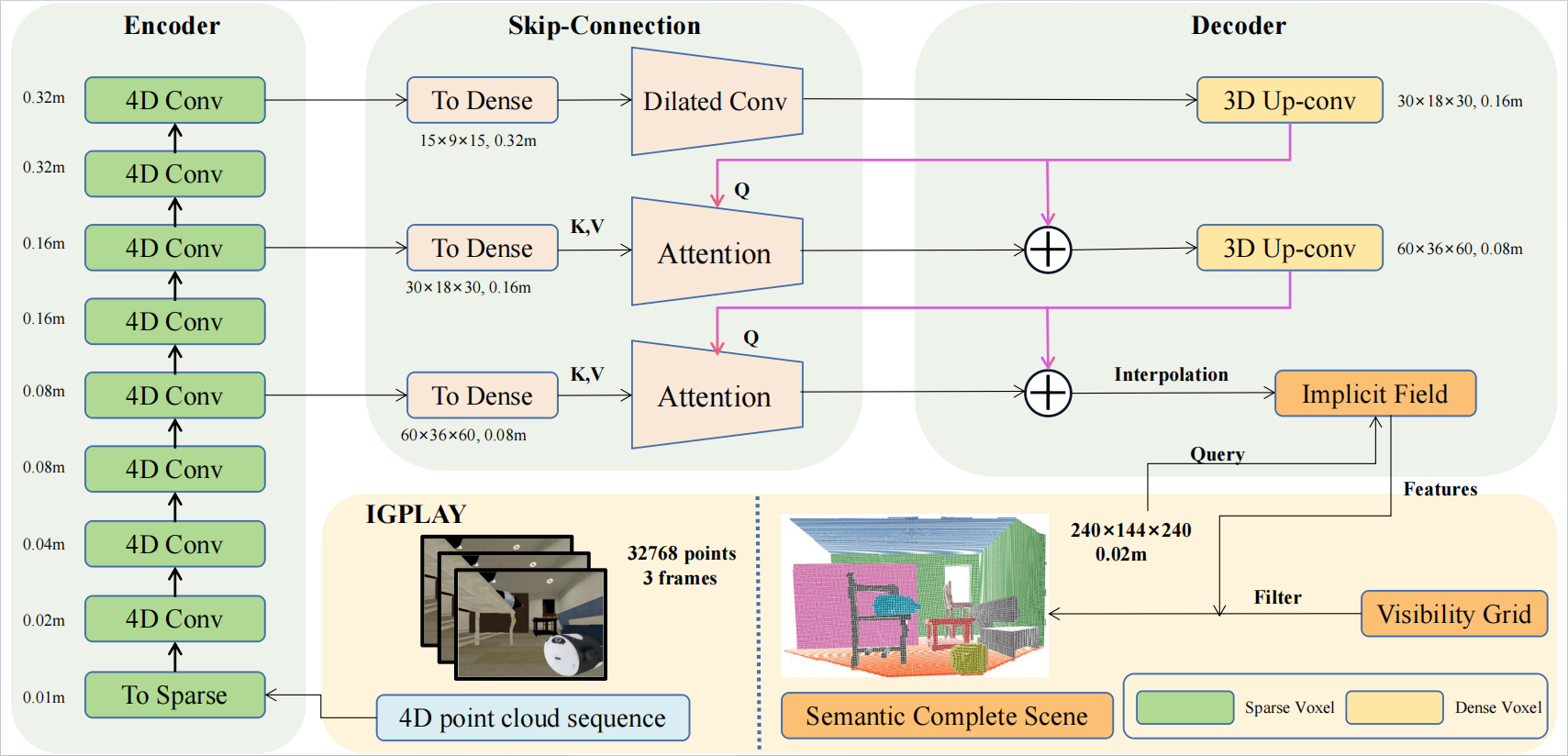
To tackle this challenging problem, we properly model the synergetic relationship between future forecasting and semantic scene completion through a novel network named SCSFNet. SCSFNet leverages a hybrid geometric representation for high-resolution complete scene forecasting. To leverage multi-frame observation as well as the understanding of scene dynamics to ease the completion task, SCSFNet introduces an attention-based skip connection scheme. To ease the need to model occlusion variations and to better focus on the occluded part, SCSFNet utilizes auxiliary visibility grids to guide the forecasting task. To evaluate the effectiveness of SCSFNet, we conduct experiments on various benchmarks including two large-scale indoor benchmarks we contributed and the outdoor SemanticKITTI benchmark.
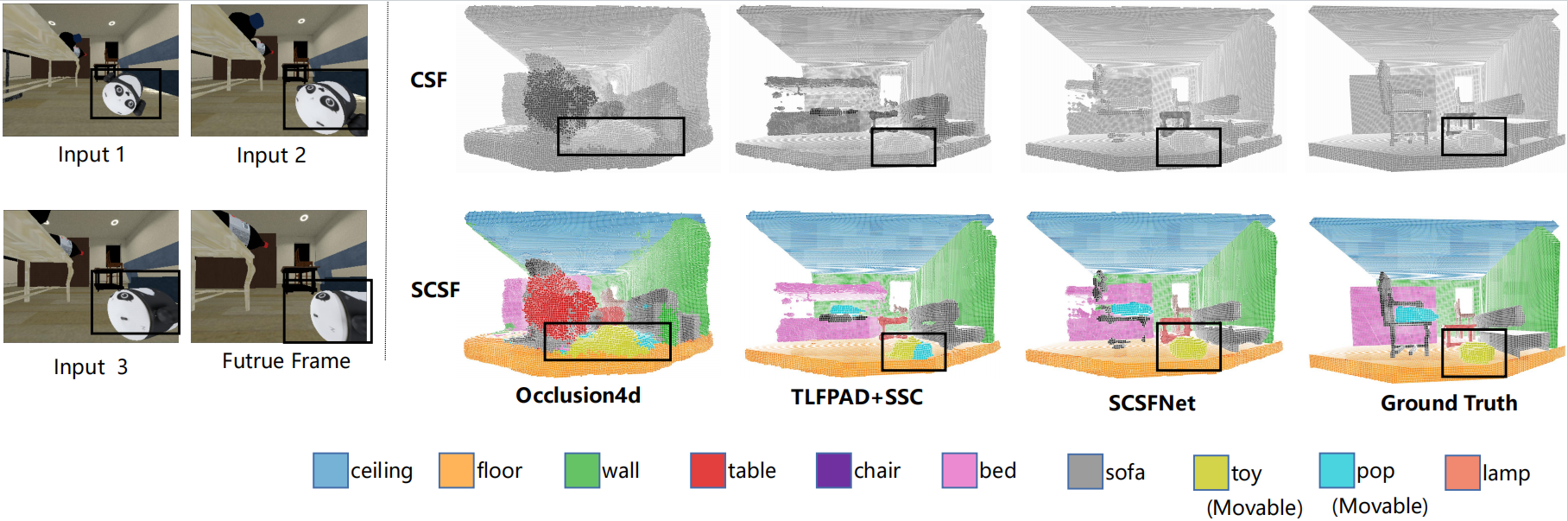
Extensive experiments show SCSFNet outperforms baseline methods on multiple metrics by a large margin, and also prove the synergy between future forecasting and semantic scene completion.
The IGPLAY dataset contains 1,000 scenes lasting 10 timesteps each, where a viewer interacts with various toys among the furniture. Each scene in IGPLAY contains 10 semantic classes in a great variety.
The IGNAV dataset contains 600 scenes lasting 10 timesteps each, where several active robots move and navigate in the scene. Each scene in IGNAV contains 9 semantic classes in a great variety.
SCSFNet, uses an egocentric 4D point cloud sequence with N frames to predict future scenes with semantic information.
It employs an encoder-decoder structure with hybrid geometric representations attention-based skip connections, and a visibility grid for high-resolution forecasting.
Our SCSFNet outperforms baselines by a large margin on two synthetic indoor datasets IGPLAY and IGNAV and one real-world dataset SemanticKITTI in different settings.
Coming soon
If you have any questions, please contact: Zifan Wang(wzf22@mails.tsinghua.edu.cn) Zhuorui Ye(yezr21@mails.tsinghua.edu.cn) Haoran Wu(wuhr20@mails.tsinghua.edu.cn).
@article{wang2023semantic,
title={Semantic Complete Scene Forecasting from a 4D Dynamic Point Cloud Sequence},
author={Wang, Zifan and Ye, Zhuorui and Wu, Haoran and Chen, Junyu and Yi, Li},
journal={arXiv preprint arXiv:2312.08054},
year={2023}
}